
Ewaluacja polskich word embeddingów
W artykule opisujemy nasze doświadczenia z używaniem “word embedingów” i prezentujemy wyniki eksperymentu mającego na celu wybranie najlepszego zestawu “Polskich wektorów słów”. Przetestowaliśmy aż 110 modeli i wybraliśmy dla was najlepszy!
Czym jest word embedding?
W wielkim skrócie jest to zapis słów w postaci wektorów. W mniejszym skrócie są to słowa umieszczone w przestrzeni wektorowej, przy uwzględnieniu znaczenia wyrazów. Tworzyć embeddingi można za pomocą sieci neuronowych, modeli probabilistycznych, macierzy współzależności itp. Najpopularniejszą formą embeddingów jest Word2Vec, który jest zbiorem dwuwarstwowych modeli sieci neuronowych. Dla lepszego zapoznania się z ideą zamiany tekstu na postać wektorową i lepszego zapozniania się z Word2Vec, Fastext i Gensimem polecam zapoznać się z poniższymi artykułami:
- Wpis wyjaśniający word embeddingi
- Artykuł prowadzący krok po kroku po bibliotece gensim i Word2Vec
- Post o tym jak działają modele Word2Vec i Fastext
- TF-IDF kontra Word Embeddings
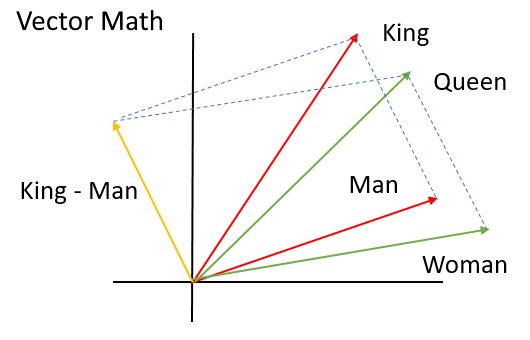
mieć taką samą odległość co Królowa do Kobiety
Założenia naszego eksperymentu
Mieliśmy problem w jednym z projektów i zastanawialiśmy się, który z udostępnionych przez IPI PAN modeli word2vec oraz polskie modele Facebook fastext będą działać najlepiej w kontekście analizy sentymentu książek. Postanowiliśmy to obiektywnie zbadać. W tym celu przetestowaliśmy:
- 106 modeli Word2Vec z IPI PAN
- 1 model Word2Vec od Kyubyong
- 2 modele FastText od Facebook
- 1 model FastText od Kyubyong
Ewaluacja word embeddingów odbywała się przy pomocy biblioteki gensim. Zapisane one były w formacie Word2Vec, czyli w postaci dokumentu, w którym w każdej linii mamy para: słowo, wektor. Użyte modele zostały udostępnione przez IPIPAN, Facebook reaserch team oraz na repozytorium Kyubyong. Testowanie word embeddingów odbywało się głównie na podstawie analogii słów oraz dodatkowo na parach słów, przy pomocy współczynników korelacji Pearsona i Spearmana.
Ewaluacja
Procedura i wyniki ewaluacji modeli oraz cały kod rozwiązania znajduje się na naszym Githubie w repozytorium Polish Word Embeddings Review.
Dane testowe
Do testów analogii został użyty plik udostępniony przez Facebook FastText, a do ewaluacji podobieństw słów wykorzystaliśmy polską wersję dokumentu SimLex999 stworzoną przez IPIPAN. Potrzebował on odrobiny modyfikacji, aby podczas ewaluacji gensim mógł odczytać i dobrze zinterpretować plik. Z pliku zostały też całkowicie usunięte columny ‘nr’ oraz ‘relatedness’. Linki do tych plików można znaleźć na dole artykułu.
Ewaluacja poprzez analogie
Ewaluacja poprzez analogie jest najprostszą i w zasadzie jedną z lepszych technik na sprawdzanie poprawności word embeddingów. Ta metoda analizuje dwie pary słów np.: Polska i Warszawa, Ukraina i Wilno, sprawdzając dystans w przestrzeni wektorowej pomiędzy dwoma wyrazami w każdej możliwej parze i liczy różnice dystansu pomiędzy nimi. W perfekcyjnym modelu ta różnica powinna wynosić 0, ale jednak życie nie jest perfekcyjne, więc zawsze mamy jakiś margines. W pliku udostępnionym przez Facebooka jest 1000 linii po dwie pary słów porozmieszczane po kategoriach takich jak np.: stolica_kraj.
Wczytanie wektorów słów i przetestowanie analogii jest bardzo proste. Wykorzystując gensim wystarczy uruchomić poniższy kawałek kodu:
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format(path_to_embedding) analogy = model.evaluate_word_analogies(path_to_word_analogy)
Na początku wczytujemy wektory wykorzystując klasę KeyedVectors, a następnie w kolejnej lini wykorzystujemy wbudowaną metodę evaluate_word_analogies dokonujemy oceny modelu podając ścieżkę do pliku z analogiami w formacie:
: capital-common-countries Ateny Grecja Bagdad Irak Ateny Grecja Bangkok Tajlandia Ateny Grecja Pekin Chiny Ateny Grecja Berlin Niemcy Ateny Grecja Berno Szwajcaria Ateny Grecja Kair Egipt Ateny Grecja Canberra Australia Ateny Grecja Hanoi Wietnam
W wyniku otrzymamy dokładność przewidywania ostatniej kolumny.
Ewaluacja przez pary słów
Ewaluacja par słów odbywa się na obliczeniu korelacji modelu z ocenami podobieństwa ludzi. Metrykami wyjściowymi są dwa współczynniki: Pearsona i Spearmana oraz procent słów poza słownikiem.
Wczytanie embeddingu i przetestowanie par słów:
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format(path) similarity = model.evaluate_word_pairs(path_to_simlex) pearson = similarity[0] spearman = similarity[1]
Rezultaty
Top 10 z 110 przetestowanych modeli word embeddingów posortowanych wg poprawności analogii
| Lp. | Name | Vocab size | Vector size | Total analogy accuracy | Pearson | Spearman | Out of vocab % |
|---|---|---|---|---|---|---|---|
| 1. | facebook-fastext-cc-300.txt | 2000000 | 300 | 0,66 | 0,369 | 0,3934 | 4,004 |
| 2. | nkjp+wiki-lemmas-restricted-300-skipg-ns.txt | 1407762 | 300 | 0,62 | 0,3875 | 0,4444 | 1,6016 |
| 3. | nkjp+wiki-lemmas-all-300-skipg-ns.txt | 1549322 | 300 | 0,61 | 0,3973 | 0,4567 | 1,6016 |
| 4. | nkjp+wiki-lemmas-restricted-300-cbow-ns.txt | 1407762 | 300 | 0,59 | 0,4132 | 0,4541 | 1,6016 |
| 5. | nkjp-lemmas-restricted-300-skipg-ns.txt | 1162845 | 300 | 0,58 | 0,4031 | 0,4508 | 1,6016 |
| 6. | wiki-lemmas-restricted-300-skipg-ns.txt | 446608 | 300 | 0,58 | 0,3311 | 0,3893 | 2,1021 |
| 7. | wiki-lemmas-all-300-skipg-ns.txt | 473000 | 300 | 0,56 | 0,3456 | 0,4025 | 2,1021 |
| 8. | nkjp-lemmas-all-300-skipg-ns.txt | 1282621 | 300 | 0,56 | 0,4127 | 0,4634 | 1,6016 |
| 9. | wiki-lemmas-restricted-300-cbow-ns.txt | 446608 | 300 | 0,55 | 0,3647 | 0,4044 | 2,1021 |
| 10. | wiki-lemmas-restricted-100-skipg-ns.txt | 446608 | 100 | 0,53 | 0,3008 | 0,348 | 2,1021 |
Jak widać powyżej, najlepszym modelem jest ten od Facebook Fasttext, uczony na zbiorze Common Crawl. Wśród topowych modeli można ponadto zauważyć parę zależności:
- Embeddingi były uczone na zlematyzowanym datascie (nie znalazłem jednak informacji, czy Facebook Fasttext uczono w ten sam sposób),
- Mają rozmiar wektorów 300,
- Występuje tu algorytm sieci neuronowej opartej na Skip-Gram,
- Algorytm uczący oparty jest na Negative-Sampling.
Na podstawie embeddingów nr 5 i 6 oraz 7 i 8 można stwierdzić, że powiększanie słownika nie ma wpływu na polepszenie poprawności analogi, ponieważ te pary modeli były trenowane na takich samych parametrach. Jednak można zauważyć, że powiększenie słownika polepsza metryki korelacji.
Podsumowanie
We wpisie przedstawiliśmy metodę wczytywania polskich wektorów słów oraz przetestowaliśmy różne ich konfiguracje. W kontekście naszej ewaluacji i eksperymentów najlepiej wypadł model Faceboo fastext.
Podobnie sprawdził się on w naszych projektach i dawał najlepsze rezultaty.
Materiały – dane i modele
Użyte word embeddingi
- IPIPAN Models (others): http://dsmodels.nlp.ipipan.waw.pl/
- Facebook FastText (facebook-fastext-cc-300.txt): https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.pl.300.vec.gz
- Embeddings from Kyubyong (kyubyongfasttext.txt, kyubyong_word2vec.txt): https://github.com/Kyubyong/wordvectors
Zbiór testowy
- Polish Word Analogy: https://dl.fbaipublicfiles.com/fasttext/word-analogies/questions-words-pl.txt
- MSimLex999 Polish: http://zil.ipipan.waw.pl/CoDeS?action=AttachFile&do=view&target=MSimLex999_Polish.zip
Zdjęcie pobrane z https://www.pexels.com/photo/view-of-a-row-256428/



{kind=link}